Recently I was tasked with creating a slack chatbot which would help users query an ecommerce website as
part of a second round interview process for a position at an AI company. While that task was interesting,
I got more enjoyment out of applying the NLP and LLM technologies I used towards a cooking chatbot. So for
my first legitimate, tech oriented post on this site, let's do a deep dive and demo how to create
a cooking chatbot using OpenAI's GPT-3 API.
The cooking website which I am pulling all the recipes and such from is based.cooking
(Thanks Luke Smith!). I actually found that this was a good website to scrape data from for this project due
to its minimalist/small nature. In total, there's around ~300 recipes, meaning it isn't necessary to take
extra steps or precautions to handle the data. In particular, what is needed to scrape the website for its
recipes is the sitemap, which is located at: https://based.cooking/sitemap.xml.
As far as software goes, I'm developing in Python3 and utilizing Langchain, Faiss, and OpenAI. These
packages make developing a complex chatbot fairly simplistic. Langchain is a framework for developing applications
with language models. It has a bunch of different tools/classes for easy development. You can find out more about Langchain
here. Faiss is a library for vectory similarity search and clustering of dense vectors.
It is what I am using to store the website data. You can find out more about Faiss here.
Finally, OpenAI (as I am sure you already know) is an AI research laboratory which makes their AI and LLMs open for use to the public, albeit
through an API. You can find out more about their API here.
Moving on, as far as the mental framework for how I am developing this chatbot goes, I've divided development into three separate steps:
- Data -- How do we get it? What preprocessing do we need to do? How do we represent the data? How do we make it easily queryable?
- Backend Logic -- How do we implement a chatbot? How do we connect our questions/queries with OpenAI and our data?
- Frontend -- How exactly are we interacting with this chatbot?
First, let's start with data. As stated previously, I am pulling all the recipes from the website using the sitemap. The Langchain framework provides a Data Loader (SitemapLoader) which automates website scraping for us. Using this Data Loader, I will then parse each webpage with a recipe into a string, which subsequently gets split into a manageable size, turned into embeddings (dense vector which represents document), and stored in a vector store. This will allow the chatbot to easily interact and query the data. Here is the code for retrieving, cleaning, and processing our data:
### Imports ### from langchain.text_splitter import TextSplitter from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import FAISS from langchain.embeddings import OpenAIEmbeddings from langchain.document_loaders.sitemap import SitemapLoader import yaml import os from bs4 import BeautifulSoup import requests import xml.etree.ElementTree as ET ## Main Function: Scrape sites -> parse into docs -> embed docs as vectors -> construct vector store ## if __name__ == "__main__": ## Step 1: Open Config File with open('config.yaml', 'r') as config: config_file = yaml.safe_load(config) ## Step 2: Get necessary api keys os.environ['OPENAI_API_KEY'] = config_file["openai_token"] embeddings = OpenAIEmbeddings() ## Step 3: Use SitemapLoader to scrape webpages docs = [] for site in config_file["web_sites"]: sitemap_loader = SitemapLoader(web_path = site) sitemap_loader.requests_per_second = 25 docs = docs + sitemap_loader.load() ## Step 4: Split docs into manageable sizes text_splitter = CharacterTextSplitter(chunk_size=8000, chunk_overlap=3000) docs = text_splitter.split_documents(docs) ## Final Step: Create vector database with openai embeddings db = FAISS.from_documents(docs, embeddings) db.save_local("./vectorstore") |
To use this script, it is necessary to define a config file named "config.yaml". This file contains API keys, file paths, and the
sitemaps to scrape:
#OpenAI Verification Tokens openai_token: "" # Vectorstore Path vectorstore: "./vectorstore/" # Website Sitemaps to scrape: web_sites: ["https://based.cooking/sitemap.xml"] |
Moving on, we now need to implement the backend logic which defines the chatbot. Using Langchain, this is fairly
straightforward. By using ConversationalRetrievalChain
we can easily define a chatbot, which uses GPT-3, that can interact and query the recipe documents. As to how I am implementing this to
make a chatbot we can easily interact with, I created a class QABot:
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import CharacterTextSplitter from langchain.llms import OpenAI from langchain.chains import RetrievalQA from langchain.memory import ConversationBufferMemory from langchain.chat_models import ChatOpenAI from langchain.chains import ConversationalRetrievalChain class QABot: """ A class to represent an AI Conversation bot ... Attributes ---------- chat_history : list of str previous messages in chat qa: ConversationalRetrievalChain LLM Conversation Chain object -- what gives us chatbot functionality Methods ------- query_answer(str): Reads a query and returns a chatbot answer clear_history(): clears chatbot history """# 'ada' 'gpt-3.5-turbo' 'gpt-4', def __init__(self, vectorstore): # Set chat history self.chat_history = [] # Define ConversationRetrievalChain using our vector store, use GPT-3.5-Turbo as our model self.qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(model='gpt-3.5-turbo'), retriever=vectorstore.as_retriever()) def query_answer(self, query): """ Respond to query using ConversationalRetrievalChain LLM model Keyword arguments: query -- the query to be answered returns: result -- response to user's query """ # Use ConversationalRetrievalChain to generate answer to query result = self.qa({"question": query, "chat_history": self.chat_history}) # Append response to chat history self.chat_history.append((query, result['answer'])) # Return answer return result['answer'] def clear_history(self): """ Clears the bot's chat history """ # Set chat_history to empty self.chat_history = [] # Return None return |
This class has two different functions, query_answer and clear_history, which are fairly self-explanatory. Query answer
takes a user's queries and then funnels them to GPT-3. Clear History clears the chat history, which is used by GPT-3 as context
for delivering answers.
Finally, we need a means of interacting with the chatbot. For my implementation, I kept things fairly simple and created a
console user interface:
import qa_ai from langchain.vectorstores import FAISS from langchain.embeddings import OpenAIEmbeddings import yaml import os if __name__ == "__main__": ## Step 1: Read Config with open('config.yaml', 'r') as config: config_file = yaml.safe_load(config) ## Step 2: Set openai api key as enviroment token os.environ['OPENAI_API_KEY'] = config_file["openai_token"] ## Step 3: Read vectorstore from disk vector_store = FAISS.load_local(config_file["vectorstore"], OpenAIEmbeddings()) ## Step 4: Instantiate QABot qa = qa_ai.QABot(vector_store) ## Step 5: Run chatbot loop while True: question = input("Input your Question: ") if question == "quit": break elif question == "clear history": qa.clear_history() else: print(f"{qa.query_answer(question)}\n") |
Testing this chatbot, here's the result:
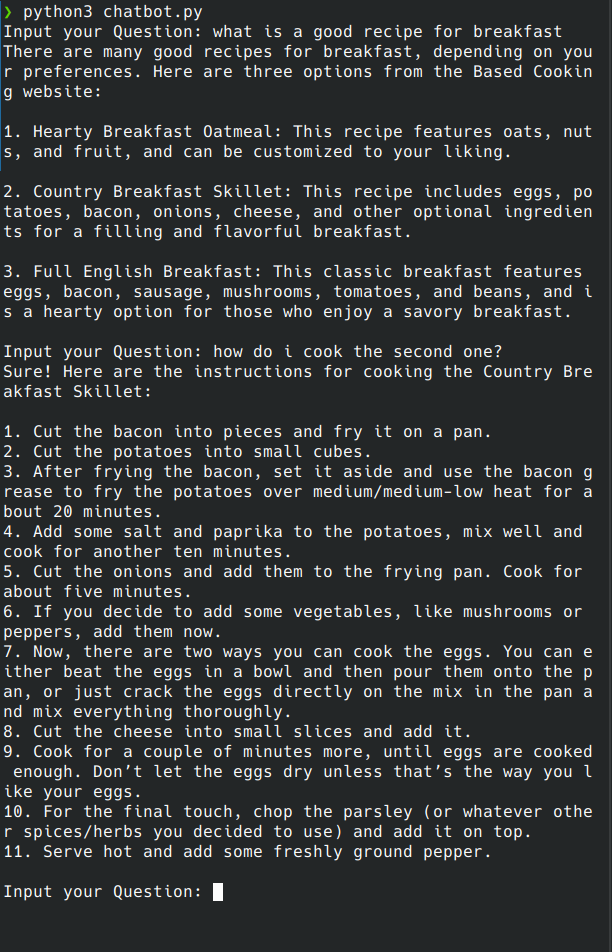
Overall, I enjoyed working on this micro project and you can find my code here: https://gitlab.com/ns-1/cooking-langbot. Enjoy 👍
--- ns1